【Tableau Tips】Tableau のカスタム形状を使い倒そう!
前書き
Tableau の形状は様々な使い方がありますが、
表の中に、カスタム形状を活用することで、ビジュアライズの幅がさらに広がることができます。
例えば、以下のような収支と進捗をまとめて管理したいときや、

顧客のステータスと直近の行動歴をまとめて可視化したいときなど。
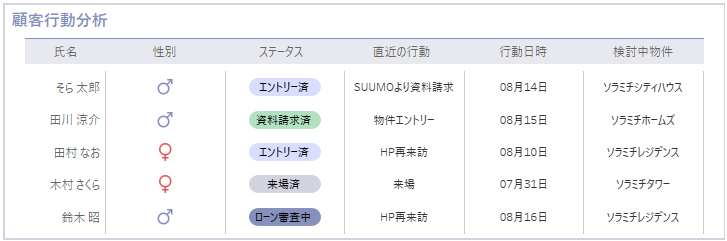
カスタム形状を使うことで、表の可読性と見栄えを簡単にレベルアップすることができます。
今回の記事では、カスタム形状の活用方法をご紹介します。
手順
Step1 : カスタム形状をインストールする
まず使う必要のある形状の画像ファイルをローカルPCのTableau フォルダ「C:\Users\ドキュメント\マイ Tableau リポジトリ\形状」に保存する必要があります。

必要に応じて、既存のフォルダに画像を入れたり、もしくは、新規フォルダを作成し、保存しても大丈夫です。
これでTableau を開いて、形状をクリックしたら、「形状パレットの選択」から新しく保存した形状を使うことができるようになります。

また、保存する画像の背景はなるべく透明のほうがよいです。なぜなら、表の中で使うときにさらに染色することもできますので、背景が透明だと使い勝手がだいぶ良くなります。
Step2 : 表の中にカスタム形状を適用する
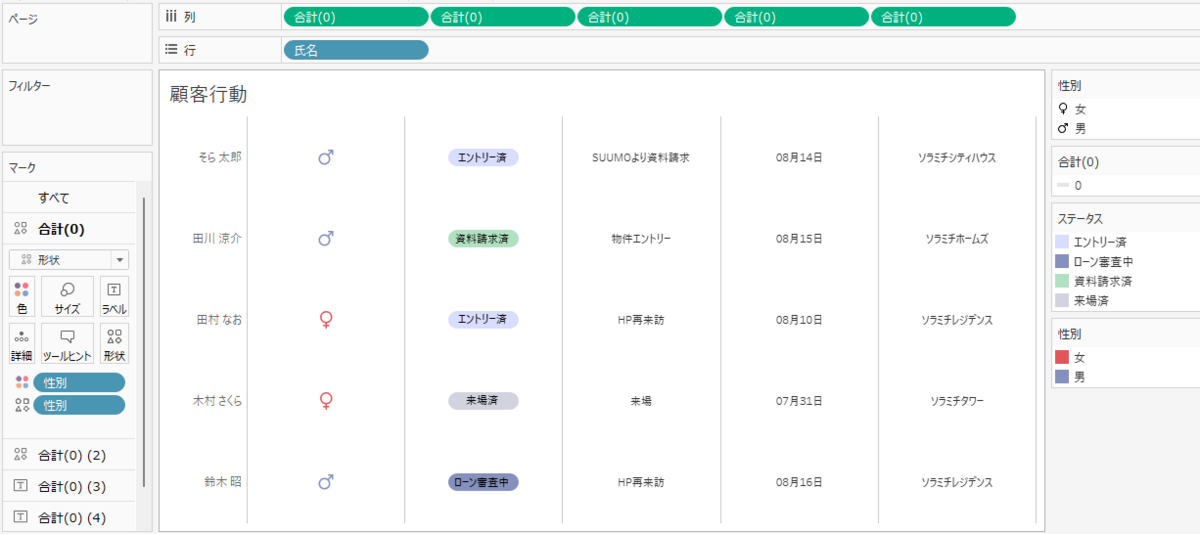
キャプチャのように、「0」という計算フィールドを作って、列に入れます。
行には使いたいディメンションを入れます。

今回はステータスを表現したいので、楕円形が一番よいので、新しく保存した楕円形の形状を選択し、適用します。

すると以下のようになります。

そこから「ステータス」を「ラベル」と「色」に両方ドロップし、必要に応じて、ラベルの位置を調整したり、色を編集したりします。

これで各顧客のステータスを表す列ができあがりました。
複数並べたいときは、最初に作った「0」の計算フィールドを列のところに並べると、綺麗な表が出来上がります。
さて、手順は以上になりますが、よかったら手元のTableau でお試しください。
Tableauで表の中にドーナツチャートを作る方法
前書き
Tableauでドーナツチャートの作り方に関する記事はいくつもありますが、キャプチャのように表の中にドーナツチャートが入って、各ディメンションが占める割合を表すドーナツチャートの作り方に関する分かりやすい紹介がなかったため、本記事を書こうと思いました。

手順
まず、「0」という計算フィールドを作成します。

続いて以下のように、二重軸を使って「0」を2回列に入れて、同時に計算方法を「合計」ではなく、「最小値」に変更します。

集計したいディメンションを行に入れます。
今回の例はデバイスごとの割合を集計したいので、「デバイス」というディメンションを適用しています。

次は、「マーク」のところからグラフの形式を変えます。具体的には:
・列の左の「0」の最小値に対して「円グラフ」を選択し、サイズもよしなに大きくするとよいです。
・列の右の「0」の最小値に対して「円」そのまま維持し、サイズを小さくし、色を白に変えます。

ドーナツチャートの真ん中に比率を表示させたい場合、集計したい指標を右の「0」のラベルのところにドロップし、配置を中央にします。

次は大事なステップで、
左の「0」に対して、「メジャーネーム」を色に、「メジャーバリュー」を角度に適用します。

すると、メジャーバリューにすべてのメジャーがまとまった形で出てきます。
このときに、「0」の合計値と集計したい指標(今回だと売上割合)だけを残します。

このあと、合計0のところをダブルクリックし、手動で「1-集計したい指標の合計値」を入れます。
例えば、今回だと、1-SUM([売上割合]) を入れることになります。
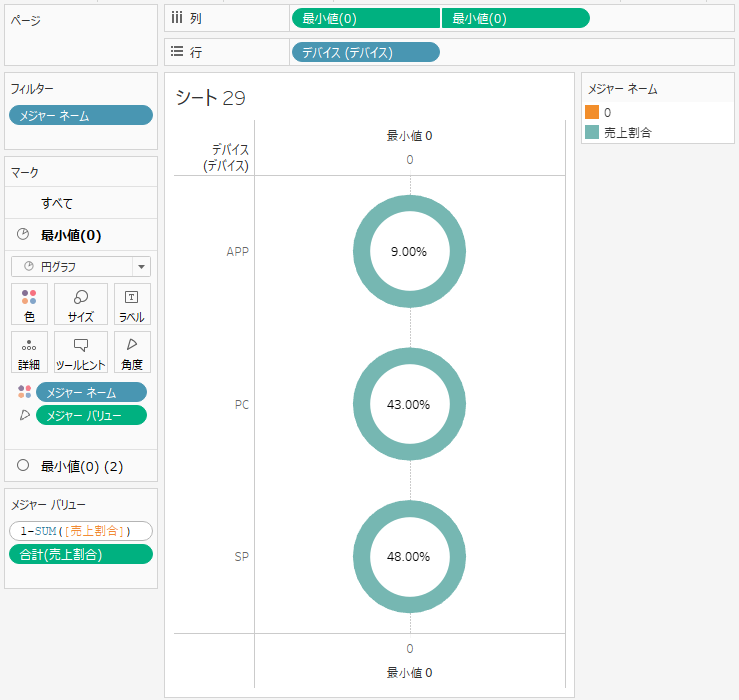
入れ終わると以下のようにグラフが変わります。

残りのステップは簡単です。色を調整すれば大丈夫です。

これで終わります。
高速な仮説検証のためのABテストの設計の流れ|後篇
以前は0から実施したいABテストを決めるための流れを紹介しましたが、本日は、実施したいABテストが個別に決まったあとに、どのように設計をすべきかについて紹介させてください。
アイディア段階に言語化すべき項目
ABテストの要件定義をよりよくできるよう、以下の項目を明確に言語化したほうが良いです。
できれば、各項目に裏付けとなるデータも合わせて記入したほうがより信憑性が上がります。
- 【WHAT】検証ポイント:だれがどのように変わるかどうか
例:サービスのTopページの検索パネルの近くに、検索履歴をちら出ししたほうが、ユーザーが前回の検索条件を便利に再入力することができ、最終的にセッション内の予約に寄与できる - 【WHY】ユーザーのニーズ:どのようなユーザーが、なにを求めているのか
例:ユーザーは検索パネルを利用する時に、前回の検索条件で再検索するニーズがある(同一セッションでTopで複数回同じ検索条件をかけるのは〇〇%;非同一セッションで、直前のセッションと同じ検索条件で再検索したのは〇〇%) - 【WHY】現状:今のウェブサイトではどのようになっているのか
例:今は検索履歴の情報は保持しているものの、サイトのフロントに表出していない - 【WHY】課題:ユーザーにとって不便・ペインを感じるのはなにか
例:ユーザーは再検索するときに、いちいち条件を入れないといけない - 【HOW】打ち手:なにをどのように変えるか
例:検索パネルの下に、一番最近検索をかけた条件を表出させる
ABテストの実施にあたって決めるべき項目
実施概要
実施概要は通常、以下の項目が含まれます:
- 実施端末
- 実施画面
- 評価指標(どの指標が有意に勝てばAB仕様を本番反映するか)
- モニタリング指標(必須項目ではない。利用する時はネガティブな現象を防ぐために設ける指標。例:予約単価)
- テストスロットの比率(100%/スロット数でOK。例:X/Aでテストする時は50%:50%でOK)
- 基準訪問数
- 最小検出可能効果
- 適正サンプルサイズ(評価指標の値と最小検出可能効果によって決める)
- 実施期間(=適正サンプルサイズ * テストスロット数 /基準訪問数)
適正サンプルサイズを決めるにあたって、A/B Test Sample Size Calculatorを使って試算すると良いです。

Baseline Conversion Rateに評価指標の実際の値を入れます。
例:予約CVR
Minimum Detectable Effectに最小検出可能効果の値を入れます。最小検出可能効果の値は通常決めです。
おすすめの決め方は、過去同じ面で実施した&有意に勝ったABの改善幅の中央値。
※改善幅 = ( Aの評価指標の実際の値 / Xの評価指標の実際の値 ) - 100%
例:過去勝利したABは計三回、一回目の改善幅は103%、二回目は107%、三回目は102%であれば、103%を使うとよいです。
Statistical Significanceに90%か95%ぐらいを入れると大丈夫です。
ABのワイヤーフレームと仕様説明
おすすめの専門ツールはsketchやAdobeなどがありますが、
エンジニアやデザイナーに意思さえ伝わればOKなので、別にパワーポイントでも大丈夫です。
仕様説明を書く時に、以下のケースに分けて書くとよりよいです。
- 初期表示:Xに比べ、初期状態の見た目の差分はなにか
- イベントの表示条件:どの状態を満たす時に、イベントが発火するのか
- イベントの要件:特定のObjectが具体的にどのような条件でどのように動くか
- 特殊ケースの処理:ある特殊のケースの時にどうすべきか
特殊ケースの処理は、最初から全部モーラーするのが難しいので、実際エンジニアたちと会話する時に、補足していくのが良いでしょう。
商品分析の第一歩|商品カテゴリ別のLTV分析
商品分析で、各商品カテゴリのパフォーマンスを判明したいケースがあります。Tableauを使って、すばやく傾向を掴む手順について、紹介をしたいと思います。
本編は、以下の順番で説明をしていきます:
1.想定ケース・利用データセットの説明
2.分析のアウトプットイメージ
3.作り方
1.想定ケース・利用データセットの説明
Tableauのデフォルトのデータセットの「Sample - Superstore」を使います。
このデータセットの中で、以下の指標を使います:
- Customer Name:顧客の名前
※本来であれば、同じ名前を持つ顧客を区別できるよう、顧客のidを使うのが理想ですが、ここはデータセットの制限を受けるため、一旦名前を使います - Order ID:予約番号
- Order Date:予約日
- Sales:取扱額
- Profit:利益
※利益=取扱額*(1- discount率)-コスト - Sub-Category:商品のカテゴリ
実際の現場では、17種の商品カテゴリを扱う売り場の責任者が、
これから投資の最適化をするために、既存の商品カテゴリの中で、どのカテゴリに注力すべきかについて知りたがっています。
分析者として、それを以下のinputを受けました:
- 商品が売れるよう、クーポンを付与して、discountをして販売をしていました。
- クーポンに対する考え方:クーポンを付与することによって、リピート率を上げたい。そのために、初回購入のときに、利益がマイナスでも、その後の購買で作ったtotal利益がプラスであれば良い。
2.分析のアウトプットイメージ
商品カテゴリ別の取扱額&売上額
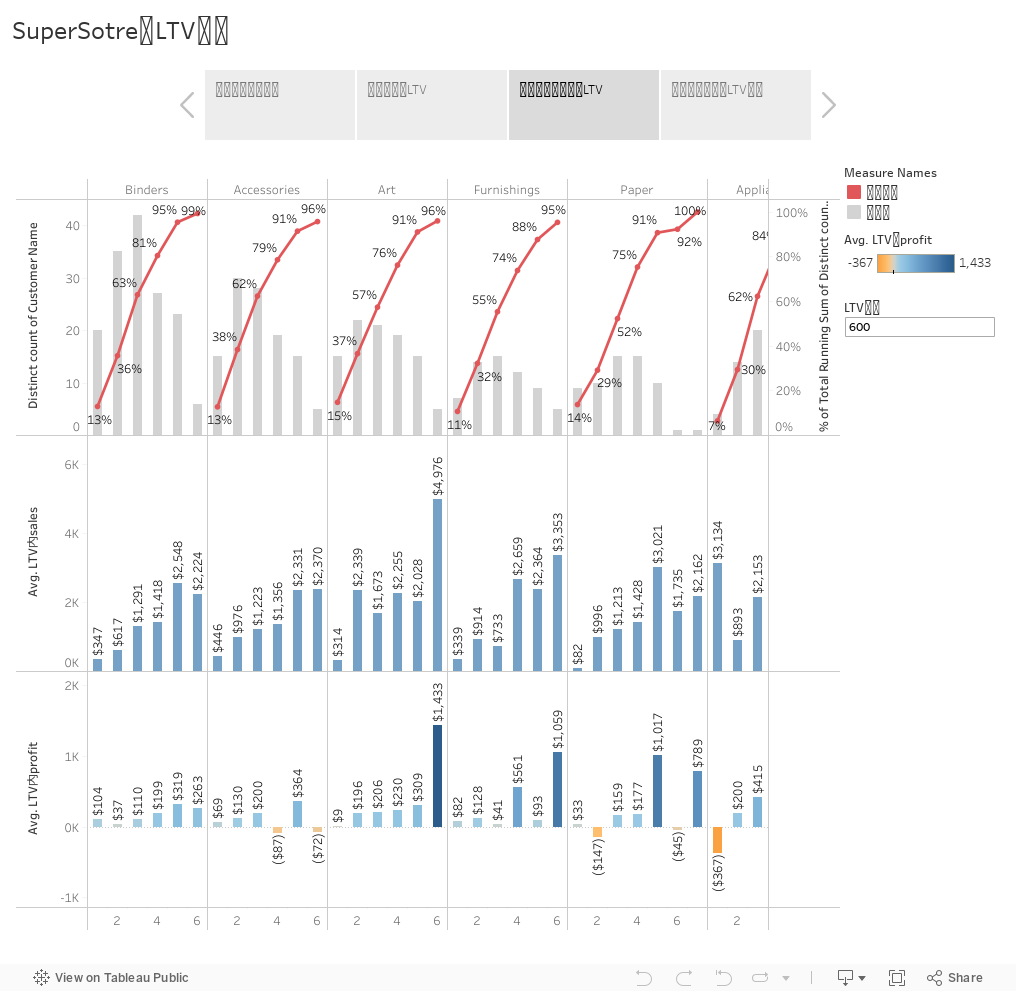
ここでは、商品カテゴリのごとに、取扱額・利益額・平均取扱額・平均利益額の分布を確認するのが目的です。
- BindersとArtは取扱額も、売上額も高い。そのうち、Artの平均取扱額と平均売上額は全カテゴリにおいて2位となる
- 利益がマイナスなのはLabels

ここまでは、通常の分析となにも変わりません。
ここからのLTV分析が肝です。
ここでは、リピート(何回まで購入し、いくら取扱額・利益額を作った)の実態を把握するのが目的です。
Life Timeを何日にしたほうが適切なのかは分からないので、最初に分析したときには、色々な日数を試しながら、あとは現場にいる責任者と話し合いで最終的に日数を決めます。
- この売場では、600日をLife Timeとした場合:
- 約8割の人が4回まで購入し、97%の人は6回まで購入した
- 7回目以降の利益が下がった

※横軸:顧客がLTV内における購入回数
ここでは、商品カテゴリ別で見て、特定のカテゴリが特にリピート率(=1-1回購入の顧客割合)とLTV内の取扱額・売上額が特に高い・低いものはないかを確認するのが目的です。
先程の全体傾向の確認で、わかったのは、6回まで購入するのが全体の97%で、以下は各カテゴリにおいて、6回まで購入した顧客のデータをみていきます。
ここで分かるインサイトが様々で、例えば:
- Appliancesは、一回しか買わない人の利益がマイナスだが、商品自体のリピート率は93%(=1-7%)でカテゴリの中では高く、また、3回まで購入した人が6割で、三回購入した人の利益額が$415で、全カテゴリの三回目に比べて最も高い
→Appliancesに初回クーポンをつけることで、一時的に利益がマイナスとなるが、その後の購買に繋がり、最終的に高い利益を生み出すことができる商材であることが分かった

※横軸:顧客がLTV内における購入回数
これを分かりやすくするために、散布図にしたら、こうなります:

3.作り方
LTVの集計で最も肝心なのは、集計上でLTVに対する定義をしっかり反映させることです。つまり:
- Life Timeを変更できるように、予めパラメーターとして設定すること
- 顧客の初回の購買日から今日までの日数がLife Timeより長いこと
- 顧客の初回の購買日から、Life Timeの日数までのレコードしか集計しないこと
という内容をTableauで計算フィルドを作るときに心がけることです。
Life Timeのパラメーター
これは簡単です。説明を略します。

顧客最後の日から今日までの日数のフィルター
まずは個々の顧客の初回の購買日を特定します。

そして、フィルター条件を作ります。フィルターにかける際に、TRUEを選びます。

顧客の初回の購入日から集計するレコード

その他の計算フィルド
LTVの場合、カテゴリや取扱額・利益額を、LTV用のディメンションとメトリックスを作る必要があります。
こちらはディメンションの初回購入の商品カテゴリです。

こちらはディメンションの購入回数です。

これからはメトリックスです。取扱額と売上額の作り方は同じです。


散布図に使うメトリックスのリピート率です。

詳細は、TableauのPublicからダウンロードしてみてください〜!
Adobe Analytics|個別概算カウント(APPROXIMATE COUNT DISTINCT)で数が合わない理由
今日は同僚に、Adobe上で、Store IDをカウントして出したいけど、
- Store IDをディメンションに適用して表示された行数
- 個別概算カウント機能でMetricsに適用して表示された値
が微妙に合わないのはなぜと聞かれました。
まず、結論からいうと、合わないのは当たり前です。
なぜなら、個別概算カウント機能は、count distinctとして表示されていますが、実質計算方法は全く別で、HyperLogLog(HLL)手法を用いて、選択したディメンションの個別カウントの概算値です。
※概算値の誤差 <= 5%
※参考:Adobe Analyticsのドキュメント:個別概算カウント(ディメンション)
似たようなAdobe関数だと、Count() 関数および RowCount() 関数があります。
この3つの関数の違いは主に以下です:
Count() 関数 & RowCount() 関数
RowCount()関数は、単に行数を数えた関数です。
SQLだと、count(1)みたいなものです。
その一方、Count()関数は、括弧に入っている1の代わりに、segmentを切ったりすることができます。
例えば、SQLのcount(distinct case when storeid is not null then 1 else 0 end)みたいなことができます。
Store IDをカウントする時に、null値に配慮できるのは、Count()関数です。
個別概算カウント & Count()やRowCount()
なぜCount()やRowCount()があるのに、わざわざ個別概算カウント関数を新しく作るかというと、
カウントしたいディメンションが、表のディメンションに入ってなくても使えるというメリットがあるからです。
Adobeのドキュメントでは、以下のようにメリット&デメリットについて説明をしています:
この関数は HLL 手法を使用しているので、Count() や RowCount() よりもわずかに精度が低くなります。一方、Count() と RowCount() の数は正確です。
つまり、正確な値というより、個別概算カウントは概算値として、
AdobeのWorkSpaceで、集計したいディメンションを入れずに、単独なMetricsとして集計することができます。
ABテスティング環境の基盤理解のための専門用語まとめ
より正しいABテストを走らせるには、基盤の仕組みや動きを理解しなければ、そもそもAB設計のミスや基盤の障害が起きた時に、対応が不可能になります。
このブログでは、自分が最近受けたレクチャーに踏まえ、勉強メモとしてまとめさせていただいております。専門家ではないため、記述の間違いがあるかもしれません。予めご了承ください。
- Public IP Address と Local IP Address
- リバースプロキシ と プロキシサーバー
- ロードバランサー と グローバルロードバランサ
- DNS(Domain Name System) と DNSラウンドロビン
Public IP Address と Local IP Address
Public IP Address(グローバルIPアドレス)とは、インターネットに直に接続された機器に割り当てられるIPアドレス。
その一方、Local IP Address(ローカルIPアドレス)とは、企業など組織の内部で運用されるネットワーク上で各機器に割り当てられるIPアドレス。(出処:IT用語辞典:e-Words)
Local IP Addressの場合、インターネットなど外部のネットワークでは無効なアドレスであるため、ローカルアドレスしか持たない機器が外部と通信するには、ネットワーク境界に設置された機器がNATやNAPTなどによるアドレス変換や、プロキシなどによる中継を行なう必要があります。
リバースプロキシ と プロキシサーバー
リバースプロキシ(Reverse Proxy)とは、クライアントとサーバの通信の間に入って、サーバの応答を「代理(proxy)」しつつ通信を中継する機能、あるいはその役割を担うサーバのことを指します。
リバースプロキシ その一方、プロキシとは、クライアントからのリクエストを代理して、クライアントを隠ぺいしつつWebサーバなどと通信するサーバを指す。企業内に設置され、認証されたクライアントだけにインターネットへのアクセスを許可するのによく用いられる。
(出処:@IT)

「リバースプロキシ」と「プロキシ」は音的に似ていますが、全くの別物(むしろ真逆のもの)だと思って大丈夫です。
イメージ的には、「プロキシ」はWebクライアント(ユーザーのブラウザ)の近くにあるもので、「リバースプロキシ」はWebサーバーの近くにあるものです。
「リバースプロキシ」は複数のサーバを束ねて負荷分散を行い、外部からは一台のサーバのように見せかけるロードバランサとしての機能を持つものでもあるため、ABテスティング環境でも使われることがあります。
テスティング環境での利用イメージは、ユーザーのブラウザから、「http://www.example.jp/」を叩いた場合、リバースプロキシはクライアントとして、リクエストをIPアドレス(例:192.168.0.111)に変換してから、事前に定められたルールに従って、テスティング環境の仮想IPアドレス(例:192.168.0.112)に書き換え、Webサーバーににリクエストを転送し、Webサーバーから帰ってきた「http://www.example-testing.jp/」(テスティング環境のURL)のコンテンツを表示させます。
リバースプロキシのもう一つメリットとしては、「セキュリティの強化」にあります。
テスティング環境では、外部からの不正アクセスを防ぐために、WebアプリケーションFirewall(ファイアウォール)などのセキュリティ対策をすれば、Webサーバ/アプリに直接手を加えることなく安全性を高められます。
リバースプロキシの実装では、有名なオープンソースソフトウェアを言うと、「Apache」や「nginx」が挙げられます。
この2つのソフトウェアの違いに関して、@ITの紹介では、以下のように
nginxはスケーラビリティを重視している。
負荷の高いWebサイトではApacheよりnginxの採用が多いことも挙げられる。これはnginxの特長の1つであるスケーラビリティの高さが反映されている、といってよいだろう。
nginxに関して、リバースプロキシとしての用途もありますが、Webサーバーとしての用途もあります。
ただし、前者のほうが圧倒的に多いのは事実です。後者として、使われる時に、htmlと画像を保存することが多いイメージがあります。
更にいうと、Webサーバーとして使う時に、nginxより、Apacheのほうが日本においてより使われています。
その一方、「プロキシ」は「ルーター」と比較したほうがいいです。
「ルーター」は家庭のネットワークで使うものに対して、「プロキシ」は会社のネットワークで使うものです。
プロキシは、通信を保管し、監視や制限などのことができるし、更に取得したコンテンツを保管(キャッシュ)することもできます。
ロードバランサー と グローバルロードバランサ
ロードバランサは負荷分散する装置(機械そのものが存在する)、また死活監視の機能も持っています。
グローバルロードバランサといった場合は、Googleのサービスを指している。
より正確な定義は以下となります:
サーバーにかかる負荷を、平等に振り分けるための装置のことを指します。
この仕組みにより、Webサイトへのアクセス集中やサーバー故障などの場合でも、アクセス中の利用者に安定したサービス提供を継続可能になります。(出処:カゴヤのサーバー研究室)
ロードバランサのメリットとして:
- パフォーマンスの向上:サーバーの追加台数分、クライアントへの応答を処理可能になる
- 可用性の向上:特定のサーバーがダウンしても、別のサーバーでサービスを中断せずに提供することが可能になる
ABのテスティング環境においては、ロードバランサはユーザーをAスロットか、それともBスロットかに振り分ける役割を担っています。
DNS(Domain Name System) と DNSラウンドロビン
インターネットでは、IPアドレス(例:192.168.0.111)を指定して通信を行います。
ただし、一般ユーザーは、これらの数字を組み合わせを覚えるのにとても困難であり、そこで、人間に覚えやすいドメイン名(例:http://www.example.jp/)を叩いて、DNSがそれをIPアドレスに変換して、通信を行う役割を担っています。
そして、DNSを司るサーバーを「DNSサーバー」と呼びます。このサーバーを通じて、特定のコンピュータと通信したり、Webサイトを表示したりすることができます。
DNSラウンドロビンとは、1つのドメイン名に複数のIPアドレスを割り当てて、クライアントPCなどからの 問い合わせごとに順番に応答していく負荷分散技術です。
つまり、DNSラウンドロビンは負荷分散を実現する方式であり、ロードバランサと似ています。
そして、両者の違いをよくまとめたのは、こちらのサイトになります:ロードバランサーとDNSラウンドロビンの違い
ラウンドロビンをわかりやすく言うと、負荷分散はだいたい2種類があるうちの「同じ役割のサーバーを2台用意して、交互に処理を割り当てる方法」のことを指しています。(出処:基本情報技術者試験ワンポイント講座)

ラウンドロビンのデメリットは、全員の役割を同じにしなければいけないため、システムやファイルの内容を同じ状態に保つのに負担がかかることです。
DNSラウンドロビンをロードバランサと比較する意味で、デメリットはあと「サーバの障害を検知できない」ことがあります。
ABテスティング環境において、DNSのウェブサービスを使ってユーザーにどの画面を見せるかの変換の手続きを行うことができます。
ABテストの設計の流れ|前篇
ABテストを言うと、ボタンを赤にするか緑にするかのイメージが強いですが、売上規模が一定以上のサービスにとって、施策によって、ほんの少しだけ予約率が下がってしまったら、数千万単位の売上損失に繋がってしまうことになるため、安易に施策を実施することができません。
それで、施策が売上への影響を把握するために、ABテストを実施し、有意に勝っていたら、施策を全展開し、本番反映に踏み切る流れが必要なわけです。
このブログを書こうと思ったきっかけは、この流れの中で、ABテストが意外と勝てないことが分かりました。
一体どうすれば勝てるかを、自分の振り返りも含め、今まで考えてきたことを整理しようと思います。
このブログに書いていることは、あくまでも私個人の理解 / 見解であるため、100%正しい保証はできませんが、「勝てるためのABテストの設計」に同じ悩みを抱える人に、参考程度に読んで頂けると嬉しいです。
AB設計のアプローチ
AB設計するには、様々なアプローチがありますが、私が今まで見てきたアプローチを分類すると、大きく2つあります。
- 調査による / 直感的なAB設計
- データ / 技術ドリブンのAB設計
【調査による/直感的なAB】は、競合と自社のインタフェースを比較する / ユーザーにヒアリング・調査することを通じて、自社が劣っているところを改善するアプローチのことです。
※こういった調査も、定性・定量的なデータを使っているとも言えるが、人の主観が決める部分が多いため、「直感的なAB設計」と呼ばせていただきます。
このアプローチの強化版もあります。
ワークショップなどの形式に踏まえ、複数のメンバーで、改善できるアイディアを出し切ってから、アイディアをグルーピングして、順序を立てて、行っていくアプローチがあります。
その一方、【データ/技術ドリブンのAB設計】は、ユーザーのアクセスログから分析し、面白いファクトを見つけてから、仮設を立てて、改善を行っていくアプローチが多いです。
※もちろん、仮設や施策を考える時に、競合を参考したりユーザーヒアリングしたりすることが多いですが、比較的に客観的に決めることが多いため、ここでは、「データ/技術ドリブンのAB設計」と呼ばせてください。
この中でも、データサイエンティストがいる部隊では、商品の並び順や広告出稿などの、影響する売上規模が極めて高いところに、機械学習などの手法を使って改善を図るケースがあります。
どちらのアプローチがより優れているという話ではなく、必要性に応じて、手法を組み合わせるなり選ぶなりにしたほうが良いと、私は思います。
そして、何よりも、アプローチ / 手法を選ぶ前に、一回のABテストをどう設計するかより、なにを改善したいかを俯瞰し、全体を捉えてから、戦略 / 方向性を決めることが、極めて重要です。
特になかなか勝てない時は、方向性があることで、テストを中断することなく、リベンジに繋げられるからです。
それでは、全体のAB戦略〜具体的に毎回毎回のABの設計までの流れを紹介していきたいと思います。
全体のAB戦略〜個々のABまでの設計プロセス
AB全体のスコープ決め
一担当者として、あるABのプロジェクトを最初に受ける際に、テストする面 / 機能の指定なりなんなりのスコープは、一定レベルまで決められていることが多いでしょう。
しかし、スコープはある程度決められているとはいえ、具体的な施策に落とすには、まだまだスコープとして広すぎます。
この時に、以下2つの視点でスコープを絞ったほうが良いでしょう。
- 技術難易度
- 施策母数となるターゲットボリュームと改善余地のバランス
■技術難易度
レガシーのサービスのほど、技術制限が多く、改善したくてもなかなかできない課題が多くあります。
その中で、技術にとにかく強く、制限を突破できるチームなら、問題はありませんが、実際の現場において、こういった課題を長年放置するケースは少なくありません。
そのために、本来は解決すべきだが、技術の壁を解決できない課題に対して、諦めなければいけないのもあります。
ここは、技術者に相談・確認しながら、ある程度主観で決めて良いです。
■施策母数となるターゲットボリュームと改善余地のバランス
テストする面(具体的なページ)は決まった以上、ターゲットのボリュームが同じでは?と、そう思う人がいるかもしれません。
しかし、そうではありません。
例えば、ページの下にあるコンテンツと、ページの上にあるコンテンツを閲覧するユーザー数はイコールではないし、ページにある機能を、使ったユーザー数と、そのページに到着したユーザー数ともイコールではありません。
こういったコンテンツや機能など、サービスの構成要素となるものをオブジェクトと呼びます。
ユーザーが、それぞれのオブジェクトをどれぐらいに接触 / 利用し、かつ、どのオブジェクトを接触 / 利用したユーザーのCVRが高いかを、施策を打つ前に、事実を把握する必要があります。
例えば、skyscannerの検索条件では、「出発地、到着地、時間、人数」などの基本検索条件もあれば、「経由地、出発時刻」などの絞り込み条件もあります。
限られた時間とリソースの中で、どの検索オブジェクトを優先に改善するかは、使うユーザー数と改善余地をバランスを見ながら、判断する必要があります。

具体的にいうと、下記のイメージで優先順位を立てたほうがよいです:

☓となる部分は、最初からプロジェクトのスコープから切り捨てたほうがよいです。
そして、△となる部分は、◎の部分を解決してから、case by caseでどちらを優先するかを決めれば良いです。
念のために、ユーザー数と改善余地が多い少ないかをどう知るかについて少し言及します。
Google AnalyticsやAdobe Analyticsなどアクセスログを簡単に取れるツールが普及している今、ツールからsession数やUU数を集計すれば、施策のターゲットボリュームを簡単に知ることができます。
そして、改善余地というのは、技術の壁をさほど持っていない前提で、その課題に対して考えられる改善すべき箇所の数を意味します。
なんとなく課題意識はあるものの、具体的にどこをどう改善するかをクリアに言えないなら、一旦優先順位を落としても良いでしょう。
このフェーズのゴールは、テストするオブジェクトを絞ることです。
つまり、【WHATを改善するか】を、オブジェクト単位まで明確に決めることです。
AB全体の方向性
AB全体のスコープを上述のように更に絞っていても、具体的にどう進むかの方向性を決めるには、まだまだ絞る必要があります。
この時に、競合比較 / ユーザー調査 / アクセスログを使った深掘り分析を通じて、ABテストの方向性とその方向性を分解できるテーマを決める必要があります。
ここで言っている、「競合比較」は、調査員によるUI/UX調査もありますが、いきなり部分的に入りすぎる恐れがあるため、まずは競合調査ツールであるeMark+やsimilarwebを利用し、定量的に把握したほうが効率的でしょう。
個人的には、eMark+をおすすめします:
- eMark+は、無料なアカウントを申請することもできます。そこで、過去一年のPCサイトのuu, session, pv/sessionなどを簡単に調べることができます。
- eMark+の月額以外に、更にお金を払えば、CV関連の指標も取れるので、今自社サービスは、競合に比べて、どの指標*1においてネガティブな差*2があるのかをまず調べたほうが効率良いです。
※補足説明:
- 指標*1:よく使うのは、量的資料(uu, sessionなど)、質的指標(直帰率、スクロール状況、PV/Session、Session/UUなど)、結果指標(予約率、予約単価など)の三種類です。
- ネガティブな差*2:競合の数値と比べると、差分はあるものの、自社が優れている指標がある項目もあります。更に強化することもできますが、レガシーのサービスのほど、まずは、劣っている項目から強化したほうが良いでしょう。
ただし、ここで、【劣っている項目】というのは、単純に数値的に競合より高い・低いという話ではなく、なにかのネガティブな理由によって、差が生じるケースを指しています。
例えば、PV/Sessionが競合より多い場合、コンテンツ系のサービスならプラスとしてみなしてOKで、予約系やECサイトなら、サイトの構造(例:同じ量のコンテンツや機能を複数にページに分割する)によって生じるのであれば、ネガティブな可能性があります。
また、ここで、ある指標がどうなったかといって、必ずしもネガティブだと判断することが難しいでしょう。
しかし、プロジェクトのスコープを絞る必要があり、その指標が一体ネガティブかどうかの検証も含め、一定の確度があれば、まず一旦その指標から深掘ってみても良いでしょう。
もちろん、その指標をひたすら上げる・下げるという話でもありません。さっきのPV/Sessionの例だと、流入してからCVまでするのに不可欠なステップがある中、必要なステップ数よりPV/Sessionが下回らないようにする必要があります。
こうやって、競合と定量的に比較することで、テストの方向性につながるなんらかのヒントが隠されていると思います。
例えば、Session/UUが低ければ、再来訪を促す方向性(例:前回訪問の履歴を引き継ぐ機能の投入やプッシュなどの集客機能の活用など)が考えられるし、PV/Sessionが悪ければ、インタラクションコストを削減する方向性(例:オブジェクトを厳選・まとめて表示・アクセスしやすくするなど)が考えられます。
このフェーズのゴールは、決めたオブジェクトに対して、どのような方向性で改善を図っていけばよいかを、具体的な言葉に落とすことです。
つまり、【HOW】を具体的な言葉にすることです。
ただし、ここで気をつけなければいけないのは、HOWのところは、具体的な施策内容やソリューション内容ではないことです。
ユーザーに提供したいUI/UXの理想像を書きましょう。
方向性に沿った施策を図るための指標設計
指標なしにしては評価することもできません。
プロジェクトも、個々のテストも、正しく評価するために、指標の設計が大事でしょう。
自己流ですが、私はABテストの指標を以下4つもレベルで考えています。
※以下は予約やECサイトを前提として考えています。
|
項目 |
利用目的 |
内容(例) |
備考 |
|
KGI |
プロジェクトを貢献を図る・評価する |
売上 |
テストの本数、テストの勝率、 テストあたりの売上と分解できる |
|
KPI |
テスト内容を本番反映するかしないか |
訪問者あたり売上 |
ABテストの場合、sample数は予め決めているケースが多いため、ここではUU数使って評価しない |
|
subKPI |
本番反映には至らないが、 施策を磨いてリベンジするかどうか |
CVR、予約/購買ごと売上など |
UU売上が有意に負けていない前提で subKPIが勝っていれば本番反映もOK |
|
マイクロCV |
施策の直接効果を図る・ ユーザーインサイトを得る |
case by case |
ここは単一指標ではなく、 複数の指標を立てて、施策ごとに選ぶ |
ここは少し補足説明をさせてください。
【KGI】
AB全体の方向性を定める際に、施策の内容以外に、
- テスト本数を増やす
- 本数を一定にするが、勝率を上げる
- 大きな改善を狙えるよう、テストあたりの売上を向上させる
など、プロジェクトベースの方向性を定めることも必要です。
なぜなら、一定期間において、より少数のメンバー・コストの投入で、より大きな売上を狙ったほうが、プロジェクトも長続きするし、評価も受けるでしょう。
【KPI】
ここでどうしてSessionベースではなく、訪問者あたりの売上(UUベース)を指標とするかは、一定期間における施策の長期的な効果と短期的な効果を両方評価しなければいけないからです。
少し極端の例を挙げると、煽り表現(例:商品残り1件)を使うと、Sessionベースでみた場合、予約率が高いが、ユーザーが急いで予約してしまったゆえに、その後のsessionにキャンセルが多く発生し、結果売上が上がらなかったケースが想定できます。
また、クーポンなどの施策も、結局新たなニーズを生み出せたのか、それとも一部のユーザーのニーズを早めただけなのかも、UUベースで施策を評価すると、より総合的に判断することができます。
ただし、集客を絡めた施策の場合(例:リスティング流入のランディングページのオプティマイズ)、集客コストへの責任もあるので、その場合は、Sessionベースの売上が有意に負けていない、かつUUベースで有意に勝っていればOKでしょう。
【subKPI】
subKPIというのは、KPI指標を分解できる指標のことです。
CVRと予約あたりの売上は、時には片方が勝って片方が負けるケースがあります。
※例えば、ホテルの予約サイトで、「カプセルホテルを除外してから、安い順でホテルをソートし、一番安いホテルを予約したい」ニーズがあります。
「カプセルホテルを除外」というフィルター機能をつけると、カプセルホテル以外の安いホテルを探す効率が圧倒的に上がるため、CVRが上がると想定できますが、予約あたりの売上が下がってしまう恐れがあります。
この時は、片方が勝っていて、そして、KPIである訪問者あたりの売上が有意に負けていなければ、OKと判断することはできます。
【マイクロCV】
ここは具体的な例を持って説明したいです。
例えば、AB全体の方向性は、インタラクションコストの削減と決めた場合、ここで考えられる指標は:
- PV/Session
- 予約までの時間
- …
などが挙げられますが、施策の内容によって、一部の指標にしか効かないケースがあるので、施策の内容に応じて、予め決められた指標リストの中から、改善できる指標を使えば良いと思います。
前篇はここまです。
次は、AB全体の方向性や指標が決まったあとに、個々のABをどう設計するかについて、紹介をしたいと思います。