インタラクションデザインについて理解しなければいけないことまとめ
本ブログは、「インタラクションデザインの教科書」をベースに整理し、自分の考えを加えたものとなります。
自分の考えも入っているため、全部が正しいわけとは限りませんが、参考として読んで頂ければと思います。
インタラクションデザインの歴史と背景
1990年、IDEO社の社長のビル・モグリッジは、自分たちが従来のデザイン(プロダクトデザインやコミュニケーションデザインなど)とかなり異なるタイプのデザインを開発をしてきたことに気づきました。
このデザインは、製品を通じてそれを使う人々をつなぐことに関係し、モグリッジがこ新しい分野を「インタラクションデザイン」と呼びました。
この背景としては、1990年代半ばに、商用インターネットが広がり、以前使用されていなかったマイクロプロセッサが、自動車・洗濯機・電話などに内蔵されるようになり、人々の生活環境のデジカル化が進んでいきました。
その中で、テレビの操作や電話のかけ方などを一から勉強する必要が生じ、日常的な物が、しばらくの間にうまく使えなくなってしまいました。
この時代の背景によって、人とマシンのやり取りを簡単にさせることが必要となり、インタラクションデザインという分野が生まれたのであろうと、「インタラクションデザインの教科書」を読んで思いました。
今や、インタラクションデザインは、世界中の何万の人々も実践する分野となりました。その一方、「インタラクション」という言葉は、多く使われている反面、実は明確的に定義されていないと主張する人もいます。
※参考:「インタラクション」とは何か? vol.1|MASA / Artrigger CXO|note
インタラクションデザインとは
インタラクションデザインは、「製品やサービスを介して人と人がインタラクション(対話)することを手助けするための技術」と、「インタラクションデザインの教科書」が定義しています。
範囲を限定して、もう少し具体的にいうと、「なんらかの「認知力」を持つ製品とは、人間に対してなんらかの判断を行い、反応を返すことができるマイクロプロセッサを伴う製品のこと」であると。
また、これは、科学というより、家具製造業のような応用美術の一種とも言えます。なぜなら、この分野には、科学的な研究法による証明や鉄則などがまだ存在していなく、状況に依存する本質があるからです。
例えば、10年前のウェブページの先進のデザインは、当時の状況ではよかったが、今となっては古く、使えにくくなっているケースが分かりやすいでしょう。
更にいうと、インタラクションデザインは、必ずしもコンピューター画面を必要とするわけではありません。
デジタルでも、アナログでも、有形(PDA)でも無形(ワークフロー)でも、また、これらの組み合わせでもあり得ます。
また、特定の技術や手段に依存するものでもありません。
インタラクションデザインは、特定の技術にとらわれることなく、目前の作業にふさわしい技術のみを考えるべきです。 そして、インタラクションデザインは、問題を解決するだけでなく、人間同士のインタラクションを、もっと豊かに、もっと深く、もっと優れたものにしていくことです。
インタラクションデザインを体系的に捉えるときの構図
「インタラクションデザイン」という分野を広く「人間工学」と呼ばれることが多いです。
人間工学の中でも、ユーザーエクスペリエンスデザインや工業デザインやヒューマンコンピュータインタラクションなど多くの領域と重なっている分野です。

ここで、特に面白いのは、インタラクションデザインがほかの領域との違いです。
「インタラクションデザインの教科書」の中で、ほかの領域に対して以下のように述べています:
- ユーザーエクスペリエンスデザインとは、ユーザーと製品やサービスとの出会いを、ビジュアルデザイン・インタラクションデザイン・音声デザインなどの側面からみて、調和を図る分野である
- 情報アーキテクチャとは、ユーザーのほしい情報が見つかるようなコンテンツの構造とラベルづけのやり方など、コンテンツ構造に関するものである
- コミュニケーションデザインとは、コンテンツを伝えるために、視覚的な言語を作ることである
- 工業デザインとは、形に関するもので、使用目的と機能に合わせて、物の形を決めること
- ヒューマンファクターとは、物が人間の身体的・心理的な制約に従うようにする分野
- ヒューマンコンピューターインタラクションは、インタラクションデザインと関連性が高く、もっと定量的な方法論に基づいている。しかし、この分野の焦点はOSなど、人間がいかにコンピューターと関係しているかにあって、人間同士の関係性について研究分野であるインタラクションデザインと違う
- ユーザーインターフェース工学は、インタラクションデザインとヒューマンコンピューターインタラクション両者の下位にあるもので、デジタルカメラの画面などのデジタル機器の制御に焦点が置かれている。その一方、インタラクションデザインは、インタフェースがインタラクションデザインにどのように影響するかという点に関心が高く、ブランドや純粋な美的要素をそれほど気にしない違いがある
- ユーザービリティ工学とは、製品をユーザーにとって、確実に分かりやすいものにするためのテスティングに関する分野である
インタラクションデザインのツールや方法論
プロジェクトに関与する前に、ビジネスが課題に直面したり、問題点が発見されたりすることが多いです。
これらの課題の中で、単純なものもあれば、もっと多いのは、「たちの悪い問題」です。「たちの悪い問題」は、以下の特徴が挙げられます:
- 問題自体が完全に理解されていない
- 境界線がはっきりしていない
- ステークホルダーがそれぞれ言いたいことがある
- 制約事項が多い
- はっきりとした解決策がない
これらの課題こそが、インタラクションデザインを携わる人が、プロジェクトに関与するきっかけであります。
インタラクションをデザインする前に、以下のこを理解する必要があります:
- ビジネスゴール:評価指標も併せて確認する必要がある
- 制約事項:ビジネス面・技術面・時間面などの制約が考えられる
4つのアプローチ

ユーザー中心デザイン
ユーザー中心デザインの哲学は、「ユーザーは何でもしっている」ということにつきます。
具体的にいうと、製品やサービスのユーザーは、何が必要で、何がゴールで、何を優先したいかを知っているので、それを探り出してそのためにデザインするのがデザイナーの仕事です。
このアプローチを取った時に、プロジェクト全般にわたってデザインを判断する決定要因はユーザーのデータです。
アクティビティ中心デザイン
焦点はユーザーのアクティビティに当てます。
アクティビティとは、目的のために行われる行為や判断のかたまりであると定義されます。「タスク」のようなイメージが近しいです。
アクティビティ中心デザインの危険性は、タスクに執着するあまり、課題となっていること全体の解決策を探さなくなってしまうことにあります。
システムデザイン
システムデザインは、分析的な方法でデザイン課題にアプローチするもので、デザインの解決策を作るために、規定のコンポーネントを組み合わせて使うアプローチです。
また、システムとは、コンピューターに限らず、人・装置・機械・ものであるケースもあります。
このアプローチは、複雑な課題に対処するのに最適であり、デザインを全体的に考えるアプローチです。
システムデザインでは、ユーザーのゴールやニーズを軽視せず、それを使ってシステムのゴールを決める一方、ユーザーの「状況」ほどに重視しない面もあります。
才能に基づくデザイン
こちらは、属人性のあるアプローチで、デザイナーが自ら持つ理解や経験でデザインを行うアプローチです。
インタラクションデザインの基本
■要素
主に「動き・空間・時間・外観・感触・音」などの要素があります
■法則
- アームの法則:時間が経つと、機械はもっと速く・小さく・強力になる
- フィッツの法則:視点から最終目標点へ移動するのにかかる時間が、目標までの距離と、目標の大きさという2つの要因によって決まるもの
- ヒックの法則:ユーザーが物事を決める時間が、選択肢の数によるものである。しかし、「ドロップダウンメニューのように選択肢を階層に分けて与えるよりも、一度にたくさんの選択肢を与えたほうがよいものがある」と異議の論点もある
- テスラーの複雑性保存の法則:プロセスには、それ以上単純化できない「臨界点」があり、それ以降は、本来揃わっている複雑性を移動できるだけ。例:メールを送る時に、長いメールアドレスを自動的に補完する機能
- ポカヨケの原則:不注意による間違いを避けることで、失敗しないことを保証する。そして、未然に防ぐことが不可能な場合は、プロセス中のなるべく早い時期に問題を阻止できるようにする
- 直接操作と間接操作
- フィードバックとフィードフォワード:ユーザーがある行動を行った時に、それにフィードバックを返す必要がある。また、フィードフォワードは、起こるはずのことを、行為の「前に」知ることである。これがあると、ユーザーが自身を持って行為を実行できる
■優れたインタラクションの特徴
- 信頼性
- 妥当性
- 賢明さ:ユーザーが間違ったり必要以上のことをしたりせずに済まなくてはいけない
- 敏速さ:0.1秒以内は即時;0.1~1秒かかれば、ユーザーは遅れを感じ、滞りとなる;1秒以上あれば、ユーザーはタスクが中断されたと感じる;10秒以上の遅れがあると,タスクが完全に断絶されたと考える
- 巧妙さ:ユーザーの要求を予測し、この欲求を予想外に気持ちよく叶えてくれる
- 遊び
- 心地よさ:機能性と美しさ
ウェブ解析×SQL×Tableau|目指す第一歩、SQLによる顧客データ抽出
以前Googleのカンファレンスで下記のデータ分析のワークフローを聞いたことがあります。

実際のところ、この4つのフローを一気通貫行うというより、「収集→保存」のフェーズにフォーカスする人/部署、また、「加工/分析→可視化」のフェーズにフォーカスする人/部署のケースが多いでしょう。
※データ量の少ない企業やコンサルティング企業では、「収集→保存」の機能に対して、専門部署を作るというより、ツールに頼っていることが多いです。
更に、一定データ量を有している企業は、自社の様々なデータをデータベースに保存しているため、データ分析をするには、まずはSQLを使ってデータ抽出から行うことが多いでしょう。
そのために、自社サービスの分析をするのに、データアナリストは:
- Adobe Analytics/Google Analyticsを使ってログデータを収集
- BigQuery上で格納されたログデータを購買データとジョインし抽出する
- Tableau上でデータ探索・分析を行う
の3つのステップを繰り返して行うことが想定されます。
本記事は、この想定シーンにおける「BigQuery上で格納されたログデータを購買データとジョインし抽出する」ところにフォーカスして、紹介していきたいと思います。
本記事紹介する内容を以下となる:
SQLを書く前に必ずに行うこと
言い方は様々ありますが、一言でいうと、「分析ゴールから分析イメージを書き出すこと」であります。
手順は以下となります:
- 分析要件を今一度整理すること
- 要件に沿って、メジャーとディメンションを設計する
分析要件の整理
分析要件を整理するには、企業によって色々なフォーマットがあります。
コンサルティング企業はクライアントに分析結果を納品する必要があるので、PPTで分析前の確認資料を作ることが多く、また、事業側はインナーのみとのやり取りとなるため、箇条書きで要点だけを書くこともあります。
分析要件は、下記の要素が含まれます:
- 分析の目的
- この分析によって嬉しい/得られること
- 分析内容
- 分析イメージ
例えば、集客施策を分析する際に、目的は、「施策効果を正しく評価することによってROIの最大化を狙う」のであれば、分析によって嬉しいことは、「最も効果的施策とその反対で最も非効果的な施策を特定することができる」。
そのために、分析内容は、「過去三ヶ月のリスティング広告の効果を比較する」とします。
最後の分析イメージは、最後に可視化する時にこう表現したいグラフまたは表を指します。
ここでは、分析前にもしすでに仮説や注意点があるのであれば、その仮説を書くことも大事です。
※仮説例:クリエイティブA案は煽り表現が入っているため、CTRが高いはず
※注意点例:クリエイティブB案の配信期間はほかのより一週間短いため、ボリューム比較する際には平均を取る必要がある
メジャーとディメンションの設計
ディメンションの設計と似たような概念だと、「ディメンショナルモデル」や「ディメンションマップ」があります。
いずれにしても、どのディメンションを持って各メジャーを比較するかをリストアップすることがマストです。
前述したリスティング広告の例では、比較対象となるのは、クリエイティブ案のほかに、検索エンジン、配信端末やブラウザ、配信時間帯など様々です。
ただし、ここで、注意しなければいけないのは、ディメンションを増やすことは、データを倍に増やしている可能性があることです。
下記の画像を見れば一目瞭然です。
検索エンジンという一つのディメンションを持つ場合は、仮にClick数とCV数を抽出するのであれば、行数は2で済みますが、
もう一つクリエイティブ案を足した場合、必要な行数は4に増えて2倍となっています。

こうやってディメンションを足すに連れ、抽出されるデータがより大きくなり、計算スピードも落ちるということは要注意です。
そのために、重くなるデータに対して、本当に必要なディメンションのみを見極めて、抽出することが大事です。
ディメンションを選択したあとに、残りはメジャーです。
※人やケースによって、メジャーを先に設計するケースもあります。
メジャーを設計する時に、4種類のメジャーを入れることをお薦めします:
- コスト系データ(例:CPC、Total Cost)
- 量的なデータ(例:Imp数、Click数)
- 質的なデータ(例:サイト内回遊率)
- CV系データ(例:登録人数、購買回数、CVR)
コストの最適化やCVの最大化とともに、時には影響を及ぼすボリュームや、CVへの間接的な影響を与える質的なデータを総合的に評価する必要があります。
また、施策全体の設計がある場合、消費者の長期的な態度変容を評価する指標を足すこともあります。
データ抽出のためのSQLテンプレート
ここのSQL構文は、BigQueryで適用する標準SQLです。
このテンプレートは、ログデータを企業の購買データと結合することを想定し、書いています。
購買データと結合するメリットはいうまでもなく、前述のリスティング広告例ですと、仮にCVは購買とすれば、リスティング流入のユーザーは、いったいなにを買って、いくら買ったかまで計測することが可能になります。
テンプレートを貼る前に、まずこういったSQLを書く時の考え方を記述したいと思います。
- 条件が多いので、基本はWITH句で徐々に書いていくことがお薦めです
- 最初のWITH句では、ターゲットユーザーを絞り出すことを目的とします
- 抽出したいログデータのディメンションとメジャーを次のWITH句で書きます
- 2と3をLEFT JOINします
- 抽出したい購買データを更に次のWITH句で書きます
- 4と5をLEFT JOINします
- あとでTableauの計算を軽減するために、ここでは一部のデータに対してflgを立てます
7について、少し補足したいです。
量のあまり多くない企業では、Tableau上で計算するのに、あまり待つことはないでしょうが、一定量以上のデータを保持する企業では、全件レコードをTableau上で計算しようと思うと、待つ時間でアナリストの心が枯れてしまうと言っても過言ではありません。
そこで、ディメンションを設計する時に、必要な情報に絞ること以外は、TableauでCOUNTD(SQLではCOUNT DISTINCT)をできるだけ使わないのと、複雑なLOD表現を使う必要な箇所に対して、予めSQLで計算させた二点に注意を払いましょう。
flgを立てることはまさに後ほどTableau上で探索・分析することをより楽にさせるための処理となります。
通常は、CVしたvisit(session)やvisitorに対して「CVしたなら1していないなら0」という処理をかけることが多いです。
※「CVしたならidを返す、していないならNULLを返す」こともSQLではできますが、後ほどTableauの計算スピードを上げるために、ここでは1と0を返すことが無難です。
テンプレートは以下のコードとなります。
実際書く時に、各WITH句をLIMIT 100で確かめながら、一個ずつ足していけば大丈夫のはずです。
最初に書く時に、どの段階でなにを抽出し、どの段階で何の計算をSQLにさせたほうがよいかが分からないかもしれませんが、実務経験が重ねればそのうち分かってきます。
Tableauでスパークラインと数字を同じ表に表示させる方法
データビジュアライズに関する初めての投稿となります。「ドキ(´Å`○)ドキ」 今日は、下記の表のように、スパークラインと数字が同じ表に表示させる方法を紹介したいと思います。

使っているデータは、相変わらずTableauのデフォルトのSuperstoreです。
スパークラインと数字を同じ表に表示させる方法
STEP1: まずはスパークラインを作成する
必要な指標とディメンションを下記のようにドロップします:

スパークラインを使っているというのは、時系列でなにかをみたい時がほとんどですので、ここでは、時間の単位(年/月/日など)を決めて、Columnsの時間のディメンションを変えます。

デフォルト設定ですと、スパークラインの軸は下記のようになっていますが、軸を揃わなくてもいいから、それぞれの分析対象の推移傾向をより詳しく見たい場合は、Rangeの「Automactic」から、「Independent axis ranges for each row or column」に変えれば、軸の最大値と最小値が最適化されます。

しかし、個人的には、推移とともに、量も把握しておきたいので、統一のままがよいと思います。
STEP2: スパークラインと一緒に表示させたい数字を、不連続と設定する
メトリックスをドロップすると、自動的に連続値として扱われますが、ここでは、「不連続(Discrete)」に変更する必要があります。

変更したあとに、メトリックスは自動的に青色になります。

ここで気をつけなければいけないのは、足していい数値の前提条件として、ディメンション単位(ここでは、sub-category)では、一つしか値がないということです。
例えば、ここで、何も処理をせずにProfitを足したら、表が崩れてしまいます。

ここでは、何を表現したいかを
スパークラインと一緒に表示させたい数値の処理について
例えば、月別でSalesの最大値を数字として同じ表に入れたい場合、計算フィールドに「MAX(sales)」だけと書いては、下記キャプチャのように、サブカテゴリのレベルに固定できず、また自動的に平均値を取られてしまうため、正解に計算されています。 今回、ほしいのは、一番右の列の数字となります。

この場合は、表計算が一番簡単かつ確実です。 具体的な作り方は、SalesのSUMに対して、下記のような条件で、表計算を加えて、それをメトリックスのところにドロップし、計算フィールドとして保存します。

最後に、それを最初のやり方に沿って、表に追加すれば出来上がります。
最後に作成したグラフをブログに埋め込みます。 ※ブログの幅が狭いから、結構形が崩れてしまっているので、できれば、Tableau Publicの私のページを見てください。
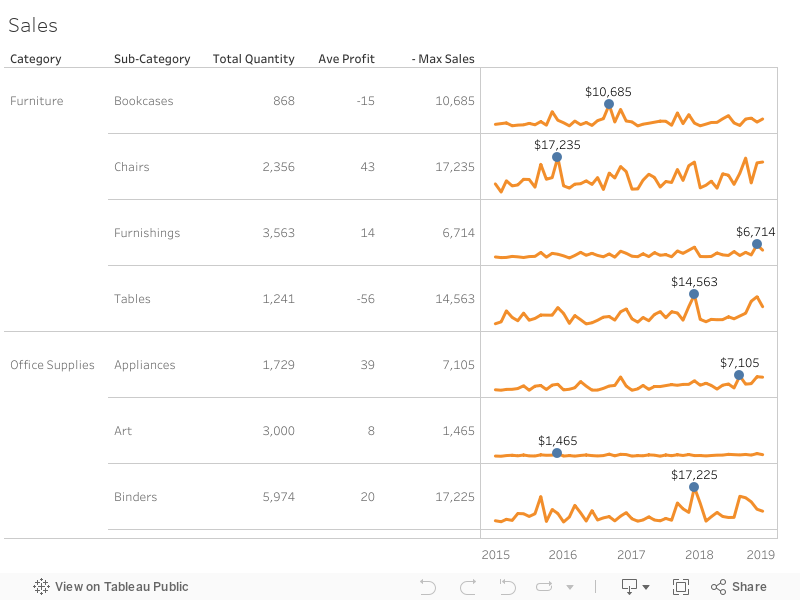
Tableau PublicビューをiFrameでサイトに埋め込む方法
最近は、「Information Dashboard Design」という本を読んでいて、これから学んだ知識をTableau上で再現し、このブログで紹介して行こうと思います。
その前に、Tableauで再現する以上は、Tableauのビューをどうサイトに埋め込むかについて、調べました。 せっかく調べたので、記録したいと思います。
もちろん、エンジニアの皆様は、直接Tableau公式のヘルプを見ればよいのですが、 私のような非エンジニアの方々に分かりやすいように、キャプチャーの手順を下記に纏めていきます。
埋め込みの完成イメージ(例)
↓は、私がヘルプの手順に沿って、埋め込んだTableauのビューです。

Tableau ServerやOnlineからでも可能ですが、私はDesktopしか使えないので、ここでは、Tableau Publicからの方法を例として紹介します。
埋め込み手順
STEP1: Tableau上でビューを構築し、Tableau Publicにアップします
今回は、Tableauのデフォルトに入っているデータ「Superstore」を例として使っています。 Tableauのナビゲーションから、「Server」→「Tableau Public」→「Save to Tableau Public」順でクリックして、その後、自分のアカウント/PWを入れれば、無事にアップすることができます。

STEP2: Tableau PublishからビューのURLを入手
ここで、気をつけなければいけないのは、URLは直接ブラウザから取ってはいけないことです。 厳密にいうと、ブラウザから取って、埋め込んでもいけますが、その場合、埋め込んだのは、Tableauのビューというより、このページ全体(ページの上のナビゲーションや下のいらない情報など)をすべて埋め込んでしまいます。
間違えた例:

望ましいのは、ビューの右下にある![]() のボタンです。
そのボタンを押せば、下記のように、「Embed Code」が出てきます。このEmbed Codeは、今回私たちが必要としている埋め込み用のURLとなります。
のボタンです。
そのボタンを押せば、下記のように、「Embed Code」が出てきます。このEmbed Codeは、今回私たちが必要としている埋め込み用のURLとなります。
もちろん、下の「Link」のところのURLでも使えます。 その場合は、下記のURLをコピーすればよいのです。
もちろん、https:から&?:showVizHome=noまでの間の部分を自分のLinkのURLに入れ替える必要があります。
<iframe src="https://public.tableau.com/views/Superstore_1398/SalesPerformance?:embed=y&:display_count=yes&publish=yes&?:showVizHome=no&:embed=true" width="645" height="955"></iframe>
STEP3: WordPressなどのエディターでコードを挿入する
下のキャプチャーのように、エディターのところで、「テキスト」に切り替えて、そのまま挿入したいところにコードを貼り付ければ、出来上がりです!

プレビューでチェックし、調整する必要なところを修正することをお忘れなく!
最後に、ご参考として、Tableauの公式ヘルプページを下記に貼り付けます:
Tableau Public ビューを iFrame に埋め込む
LaTeXiTを利用する上のベーシックコツ|知らないと損をする!
最近はEvernoteで統計のメモを作っているので、数式や記号を書くのに悩んでいましたが、 つい先週末にLaTeXiTに手を出しました。笑
早速、LaTeXiTのインストールについて紹介します。
LaTeXiTのインストール
ソフト自体は、LaTeXiT←こちらのリンクからダウンロードすることが可能です。
Macでは、ほぼ一発でインストールできますが、Windowsだと面倒くさいので、ここでは、略させてください。
LaTeXiTのコツ
LaTeXiTの基本のコマンドは、次回更新するんですが、 まずは、使う前に、いくつか知っておいたほうが良いコツを紹介したいと思います。
数式の画像
数式の画像のサイズや色自体を変更することはできます。 まずサイズは、左下の「Font size」では、デフォルトで36になっていますが、 必要によって、カスタマイズで定義することができます。

そして、「Color」のところで、色を指定することもできます。
一点だけ補足したいのですが、Font sizeが小さく/大きくなるときに、画面で表示される画像も小さく/大きくなります。 そのときに見にくいので、表示画面の右側の矢印っぽいものを上下ずらすことで表示された画像を調整することができます。
例:下記で、元々小さすぎる画像を、矢印っぽいものを上にずらすことで、ツール上でみやすくなっています。
変更前 →変更後
→変更後
過去の履歴
過去の数式をもう一度書きたい、または、過去の数式の元で更にカスタマイズしたいケースがよくあると思います。 その時は、「History」から「Show History」、またショットカットで「Command + R」過去の履歴を見ることが可能です。

もう一度入れたい数式をダブルクリックすると、自動的に再表示されます。
非エンジニアが効率的かつ高速にSQLを学習する方法
仕事のニーズもあり、6月末までにSQLを習得する目標を立てました。 最近はプライベートの時間を使って、SQLの勉強法をぐぐっていました。
非エンジニアの私は、プログラミングの勉強でも、ほかの数学や統計の勉強でも、 やはり概念を一通りに頭に入れながら、練習問題を解いていくのが最も効率かつスピーティな方法だと思います。
そのために、私が今使っているものを紹介するとともに、SQL初心者に最も良い練習サイトの答えも掲載していこうと考えています。 また、ここで私が書いた答えは、あくまでも非エンジニアかつ勉強したばかりの初心者としての記録であるため、必ずしも一番の正解だと思わないでください><
SQLの勉強にあたって、利用可能なサイトや本
サイトには、SQL以外にも、PHPやWordPressなどの紹介があります。 このサイトを載せるのは、SQLは軽くググって、漠然としたイメージを持つ段階で、このサイトに非常に簡潔にまとめられている文章を読むと、理解がかなり深まります。

見ているとおり、DBMSの基礎知識から、実際のSQL言語まで、必要最低限な知識を一通りまとまっていて、サイトのUIも非常に優れているため、おすすめします!
私も最初にぐぐって、たどり着いたのはこちらのブログでした。 実際、今日このグログで掲載する練習問題のサイトも、このブログ経由で知りました。
勉強法を、このブログも非常に詳しく紹介しているので、ぜひご一読ください。
本:10年戦えるデータ分析入門 SQLを武器にデータ活用時代を生き抜く
こちらの本ですが、実際先程紹介したGunosyのブログで知りました。 この本は、私はまだ途中までしか読んでいませんが、 SQLの知識を体系的に一通りイメージを付けるのによさげです。
例えば、window関数やアクセスログの解析など、高度な知識もまとめられていて、 かつ、実務のイメージやノウハウも含まれるので、イメージ付けするのにいいと思います。
もちろん、実際SQLを身につけるには、大量な練習問題を解く必要がありますが、 この場合は、以下のサイトから着手するのはおすすめです。
このサイト!私のfavoriteです! まるでpythonを勉強するのに、checkioの存在のようで、下記の3つのメリットがあります:
- 文法が紹介されているだけでなく、文法ごとに大量な練習問題があります。
- サイトは、英語/日本語/中国語三ヶ国語で閲覧することが可能です。
- サイト上で、直接SQLを書くことができますので、ぜひ色々書いてみてください。
こちらの練習サイトも、かなりの頻度で使いました。
良い点としては、知識の整理がまとまっていて、UIが見やすくて、豊富な練習問題もあるところです。 しかも、練習問題の答えは設問のすぐ隣にあって、少しつまずいたときにすぐにヒントをみられることができます。 ただし、細かいUX的なところで、練習問題で設問の説明が十分じゃなかったりするところがありますが、 良さと比べれば、そこまで気にしません。
最後に、ご参考ですが、私がSQLZOOで解いた問題をGithubに記録しました。 一部日本語の訳のない練習問題に対して、英語のまま記載させていただきました。 もし、より良い答えがあれば、ぜひ優しく教えていただければ幸いです。
https://github.com/RaNxxx/sqlzoo_answers
↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑
pythonエラー|array must not contain infs or NaNs
array must not contain infs or NaNs
の意味は、インプットされたarrayの中に、無限大(inf)または数値ではないデータ(NaNs = Not a Number)が入っているため、必要な処理ができません。 これを解決するには、1)インプットされたデータの中で、infまたはNaNsが入っているところを特定;2)特定された箇所を解決(0に変換など)の2つのステップが必要です。
私はsk-learnでモデルを構築するときに、DataFrameを説明変数に入れたときに、このエラーが出ました。 そのために、ここでは、これを背景に、解決方法を記録します。
エラーのキャプチャー
エラーが出たところのキャプチャー:

そして、ここでインプットされたXとYは以下の通りです:

解決の手順
STEP1 NaNsの確認
df.isnull().any()
で一発でNaNsの確認ができます。

さて、問題が発生したのは、Xではなく、Yだということがすぐに分かります。
欠損値の削除に関して、こちらの文章(https://note.nkmk.me/python-pandas-nan-dropna-fillna/)でとてもまとまっているので、詳細はここで纏まりませんが、必要な処理:NaNを0に変換するステップのみを紹介します。
#Yは入れ替えたい引数である Y.fillna(0)
これでもう一度sklearnでrunしたら、うまくいきました。